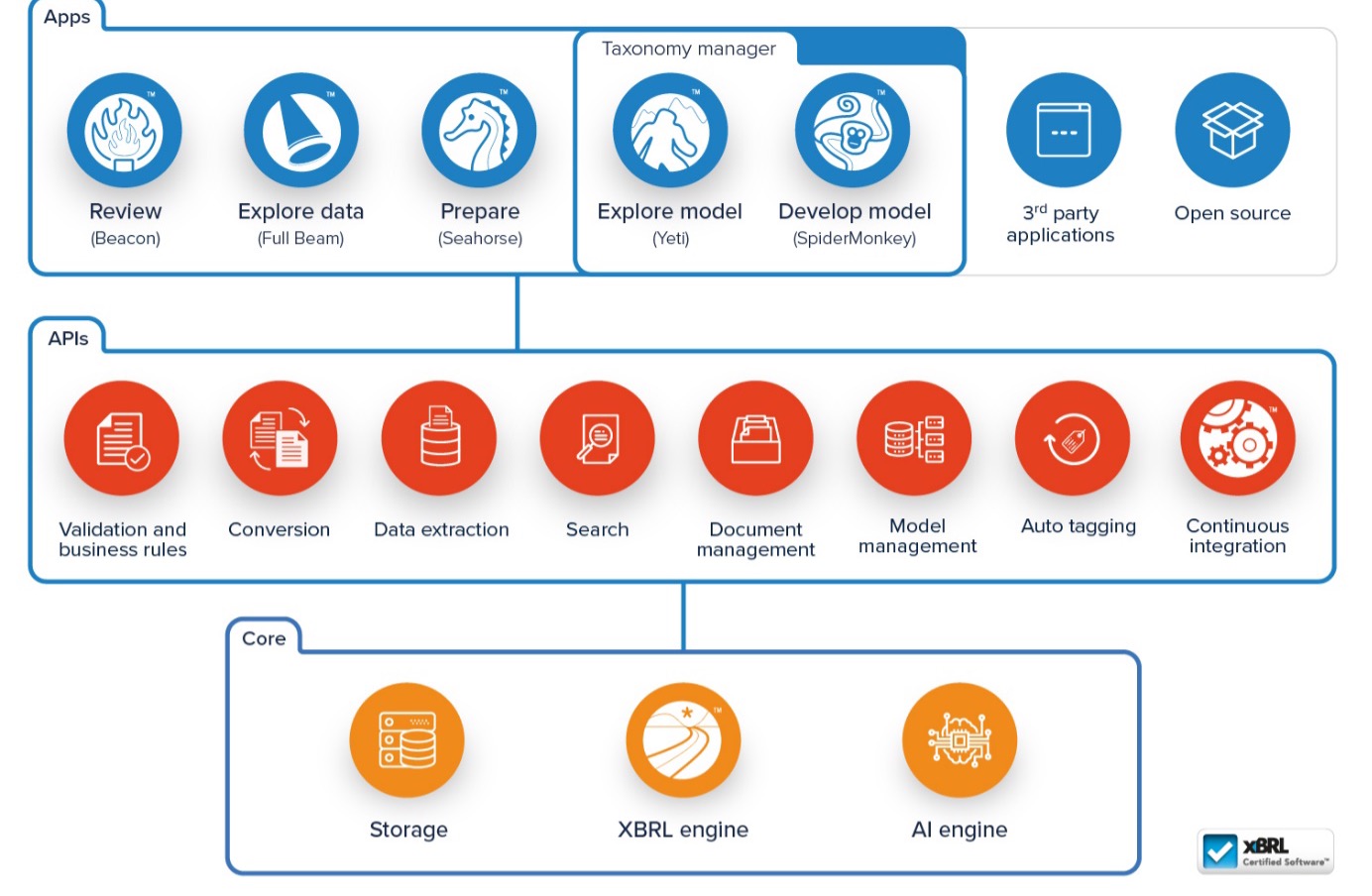
Background
Modern Data Engineering involves creating and maintaining software and systems for accessing, processing, enriching, cleaning data and orchestrating data analysis for business purposes. Data engineers build tools, infrastructure, frameworks, and services. In smaller companies — where no data infrastructure team has yet been formalized — the data engineering role may also cover the workload around setting up and operating the organization’s data infrastructure. In other words, data engineering alone doesn’t reveal insights; it readies your data to be analysed reliably.
The core related disciplines in and around Data include Software engineering, Big Data, Data engineering, business, programming, ML modelling, ML Deployment, Databases, Data wrangling, Data visualisation, Statistics and the like. It should be noted that in the overall ecosystem of building the Data platform that serves business priorities, the key responsibility areas for a Data Engineering practice will encompass significant work in Big data, software engineering, programming, data engineering, data base and ML deployment. We will elaborate the key components in this blog.
Key technology frameworks
If we consider the end-to-end value chain beginning with Data discovery, proceeding through data ingestion, data curation, data quality, data analytics followed by data science and eventual consumption by Business processes, the key activities within Data engineering include the following.
- Data Collection: Data needs to be collected from various sources – logs, a variety of enterprise grade databases, external sources such as social media, government portals etc, user-generated content, sensors, instrumentation, etc.
- Movement and Storage of Data: This involves crafting the data flow, building the pipelines, storage of structured and unstructured data, ETL, and hosting infrastructure.
- Data Governance: This includes pre-processing, cleaning and curating data in order to make it consumable by any downstream application. This will also involve data transformation, analysis, and modelling for purposes such as reporting.
A Data engineer is someone who is very good in the theoretical foundations of data structures and algorithms, database systems and query optimisation, big data systems and frameworks, data ingestion frameworks, programming languages such as Java and Python, Apache Spark, Scala, Docker, Java, Hadoop, and Kubernetes NiFI.
Software required for Data engineering
Whilst providing provisions for the Data platform, it is natural for developing software relevant to execute all the various desirable functions of an enterprise class platform. Software needs to be built in order to provide for functionalities such as data discovery, data ingestion from multiple enterprise class software systems, data ingestion from external data sources, data ingestion from subscribed data, data discovery, data cleansing, data enrichment, data auditing, data exploration, data deduplication, and data curation. These programs are better provided for in a centralised manner. Some of these functionalities are available via off the shelf applications. Some need to be custom built. However, in order to satisfy the data requirements for the organisation, it is imperative to architect the associated software in such a manner that it is usable, scalable, secure, performing and available. Data governance is an emerging corporate function that ensures the development and maintenance of these software programs.
DataOps as an enabler
As organisation’s priorities change, so do the features and expectations from underlying software that drives the organisation. Data is no exception in that regard. As business requirements change, it is to be anticipated that data projects also slip in terms of their schedules. This may result in dissatisfied customers. Sometimes the inflexibility in the development process for legacy software may also result in such experience. Finally, without proper validations put in place for Data software deliveries, one has to only expect Quality loss and low ROI apart from missed features in releases.
In order to address these challenges, the Agile ways of developing traditional software is melded with statistical quality control techniques for data fool-proofing and the Dev Ops methodology for deploying Data software. This new approach has been termed as DataOps. This approach facilitates quicker iterations in data projects, ensuring a constant tab on user requirements and experience, pivoting the teams frequently on priorities, delivering features in short increments, extensive possibly automated quality testing of data pipelines and seeking constant stakeholder feedback.
A dose of DevOps to support the innovation pipeline that is the concern of traditional software developers, along with the value pipeline that is the purview of the data engineering team, ensures that the ROI on data programs is significantly higher than what they turn out to be.
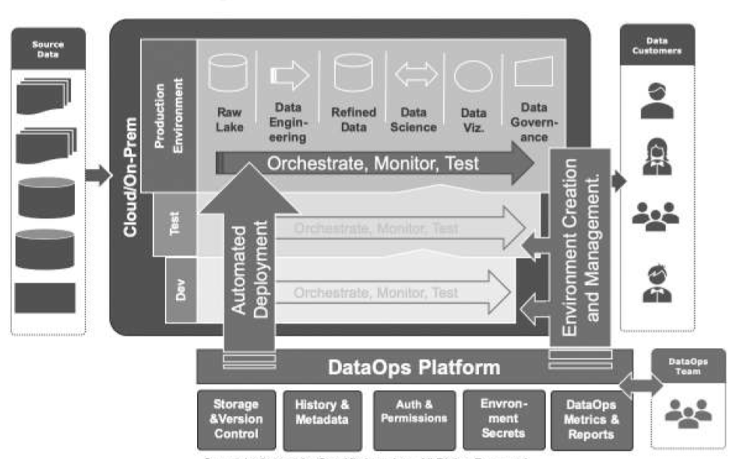
Conclusions
Over the past decade, strides in distributed data bases, parallel computing, memory architectures, networking have enabled highly efficient and cost effective ways of managing enterprise class data systems. Ensuring that the business requirements are catered to by data platforms is tightly coupled with the appropriate choice of the architecture and software systems adopted to build and maintain such platforms. Data engineering is an emerging practice that needs to be carefully thought through and embraced.