

Background
The application of mathematical methods and computer science techniques coupled with statistical modelling on industrial data has been around for several decades. However, in their new avatars of Data science and Machine learning, they seem to have garnered more than the normal mindshare of modern CEO’s. This can be easily explained when seen in the background of a more intense competition at the global scale driven by customers’ ever-changing needs and wants in an increasingly saturated marketplace. The following drivers for their adoption, are also in order:
- General recognition of the untapped value hidden in large data sources.
- Consolidation and integration of database records, which enables a single view of customers, vendors, transactions, etc.
- Consolidation of databases and other data repositories into a single location in the form of a data warehouse.
- The exponential increase in data processing and storage technologies.
- Significant reduction in the cost of hardware and software for data storage and processing.
While Data science is largely concerned with the extraction of meaningful patterns in data unseen to the human eye, AI as applied to practical cases is applicable in processing massive scale of unstructured data such as text, images, video, and speech. Parallel computing and cloud technologies have made access to computing power a lot more affordable. This enables building real applications embedding Data science and AI.
The need for models
The basic building block for Data science or AI are models. Models are an abstract representation of reality. In order to understand the dynamics of a system, it is often easier to work with the model of a system than the real system itself. Manipulating a model (changing decision variables or the environment) is much easier than manipulating a real system. Experimentation is easier and does not interfere with the organization’s daily operations. There are further advantages of modelling in general as illustrated below:
- Models enable the compression of time. Years of operations can be simulated in minutes or seconds of computer time.
- The cost of making mistakes during a trial-and-error experiment is much lower
- The business environment involves considerable uncertainty. With modeling, a manager can estimate the risks resulting from specific actions.
- Mathematical models enable the analysis of a very large, sometimes infinite, number of possible solutions. Even in simple problems, managers often have a large number of alternatives from which to choose.
- Models and solution methods are readily available, thanks to the open-source community, academia, and the large cloud technology vendors.
Some classes of models include the following: Classification and clustering, Regression for forecasting, time series methods for predictions, Markov models for segmentation, machine learning for fraud detection, etc.
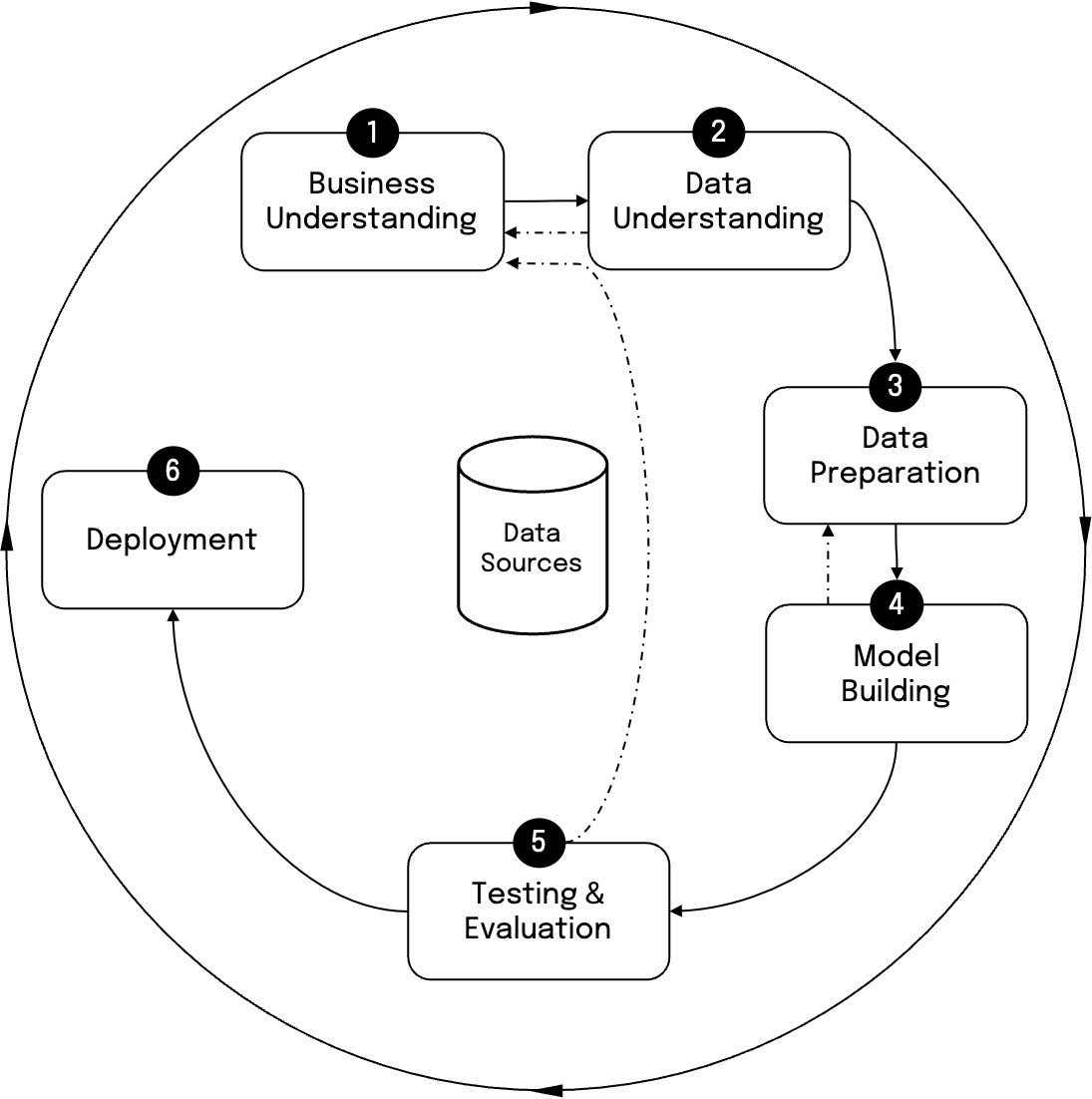
Frameworks for Data Science
Whilst academia are busy churning out new models literally every day, it is important to institutionalise the process of building, validating, and deploying models in real-world instances. This calls for a standard process to be adopted such as the CRISP-DM approach for data sciences as illustrated in the figure above. This methodology starts with Business understanding. This includes working closely with various stakeholders in the business to understand their pain points be it in operations, planning, or decision making.
This is followed by understanding all the pertinent data to be considered for solving the problems identified. Usually, the Data lake serves as the starting point to gather all relevant data touching various business processes. Data preparation then consumes a large amount of time, as in many real world settings, the data tends to get polluted. Some fields may be missing, some duplicated, some outright wrong. A host of methodologies are adopted to cleanse the data and ensure it is suitable for any analysis.
The next phase is where data scientists actually spend their intellectual time in devising new approaches for solving problems. The models built are tested to satisfy the needs of either the business stakeholders or the regulators where required. Validated models are then deployed in production grade servers. The models may degrade in performance over time. This calls for refining the overall approach or the models built thus far. This approach for Data science or AI is practiced by large organisations desirous of adopting Data science in real world problem solving.
A practical case
A Large multi-national Bank LMN is faced with the issue of customer attrition in one of its recently introduced product lines. I would like to understand why this is happening and intervene with customers well ahead of time to plug the attrition. It may be noted that the cost of acquisition is significantly high in many Banks. LMN Bank commissioned a data science project within its Credit card business. The relevant data pertaining to the product including the customer master, the transactions data, external data including from the likes of Experian, regulatory data, customer service information from call centres, were all assembled in a Data lake.
Data engineers worked round the clock to ensure that the relevant data is cleansed and made ready for analytics. The team of data scientists started with exploratory analysis by segmenting the customer base. They then looked for patterns in the credit card transactions immediately prior to attritions happening. The study also delved into the time it took for the customers to use the product and leave it too. Models including the likes of generalised linear model with logistic regression, random forests, survival analysis were used to identify a scoring methodology for predicting the customers most likely to churn, and the most likely period that they will start disengaging with the product.
A pilot study was done to intervene customers predicted as most likely to churn. It was demonstrated that offers sent to customers at the right time helped to retain those customers for a much longer period than normal. Close to 30% of such cases were saved due to proper application of data science.
Conclusions
While data is the new oil that runs any enterprise, leveraging the maximum from data in the form of insights, intelligence, and then taking action to ensure profitability is the domain of data science and AI. With proper capability building, investments in tools and frameworks, as well as adopting best-in-class processes to run this like a factory, it is possible to realise quick ROI from Data science and AI.
